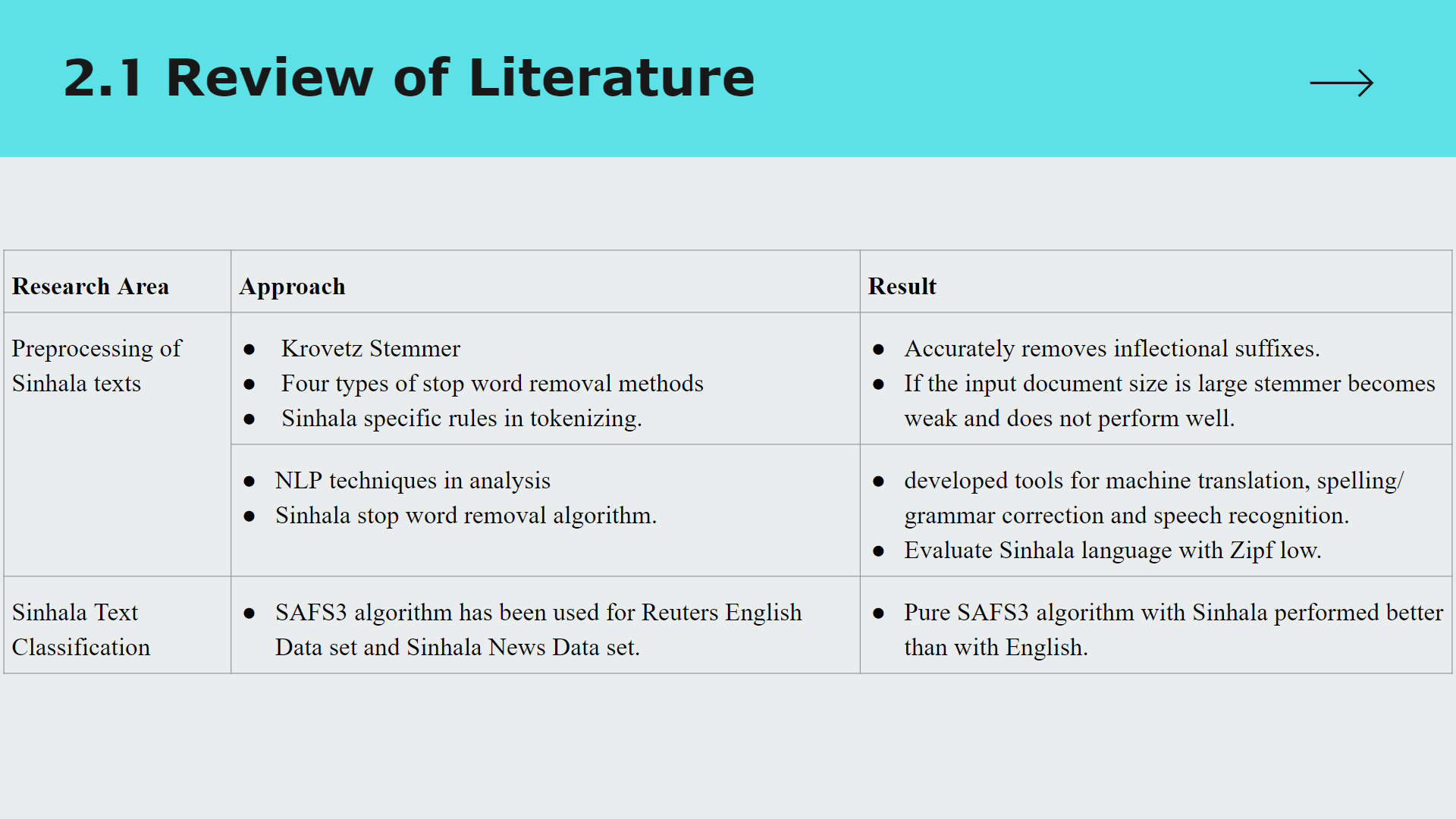
• Researched developing a tool to detect Sinhalese language-based hate speech and analyze the intention of tweets.
• Semantic analysis and data mining techniques used in addressing the problem.
• Technologies used: Python, NLTK, Pandas, NumPy, Scikit-learn, PyCharm.
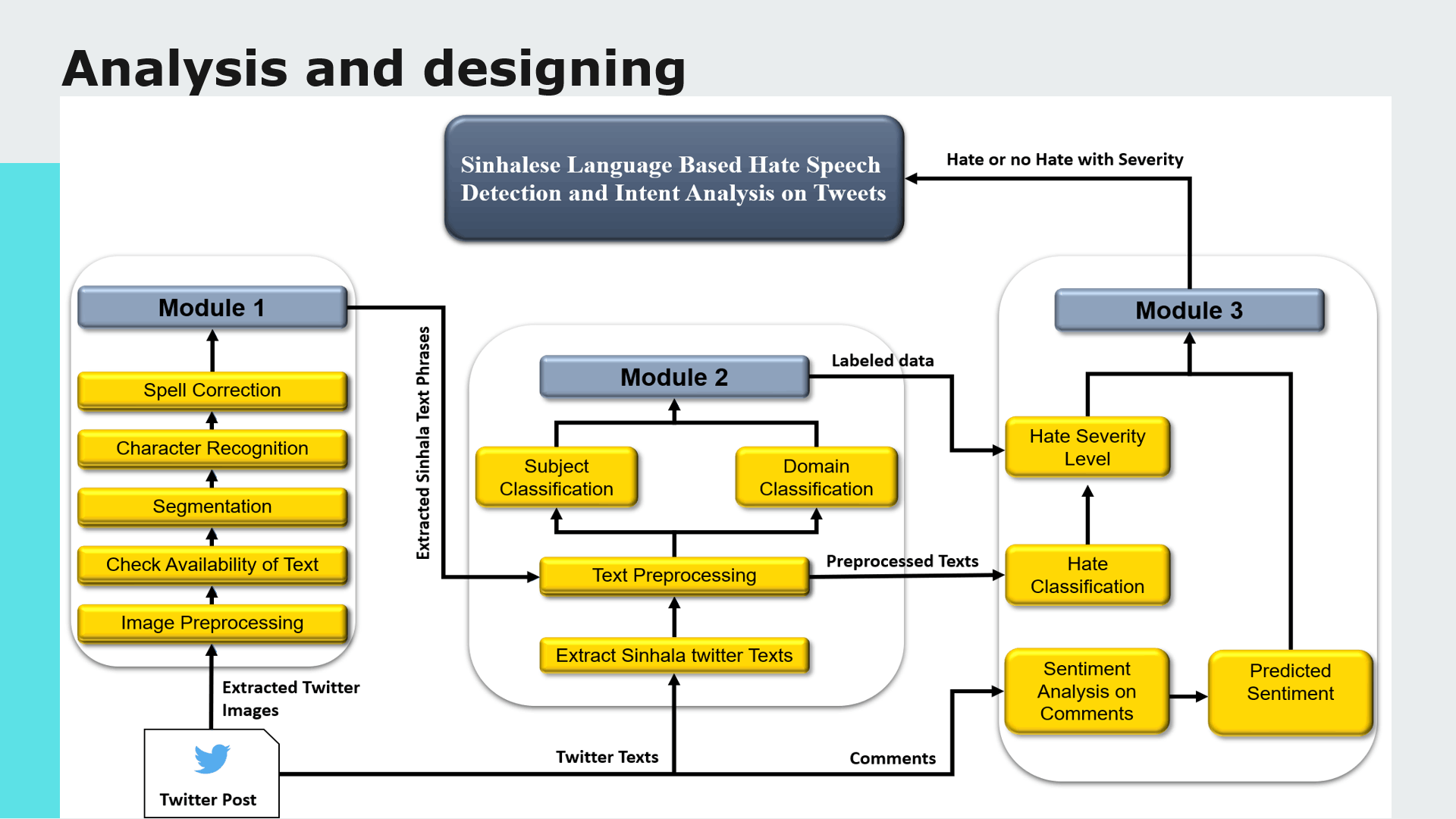
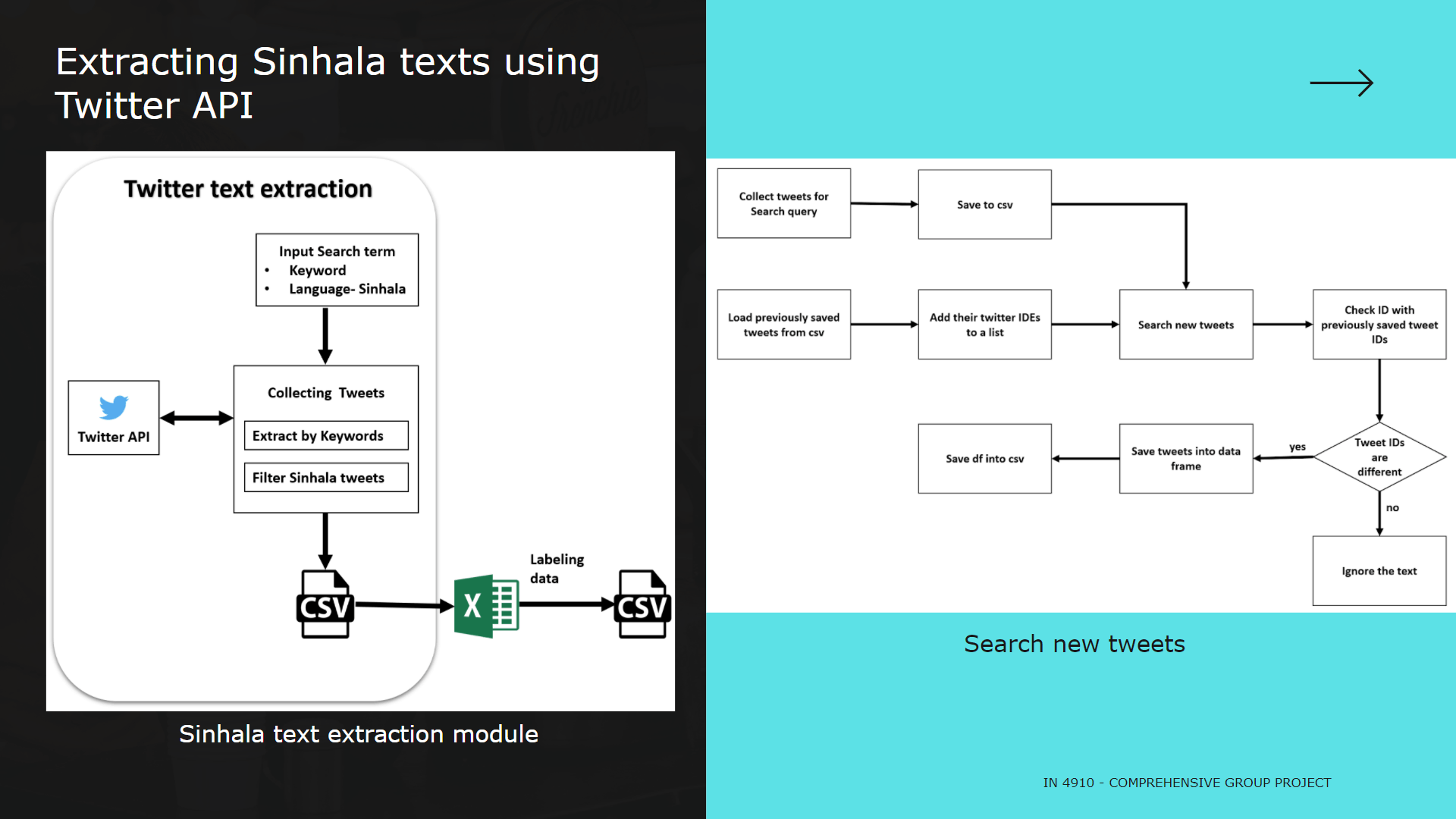
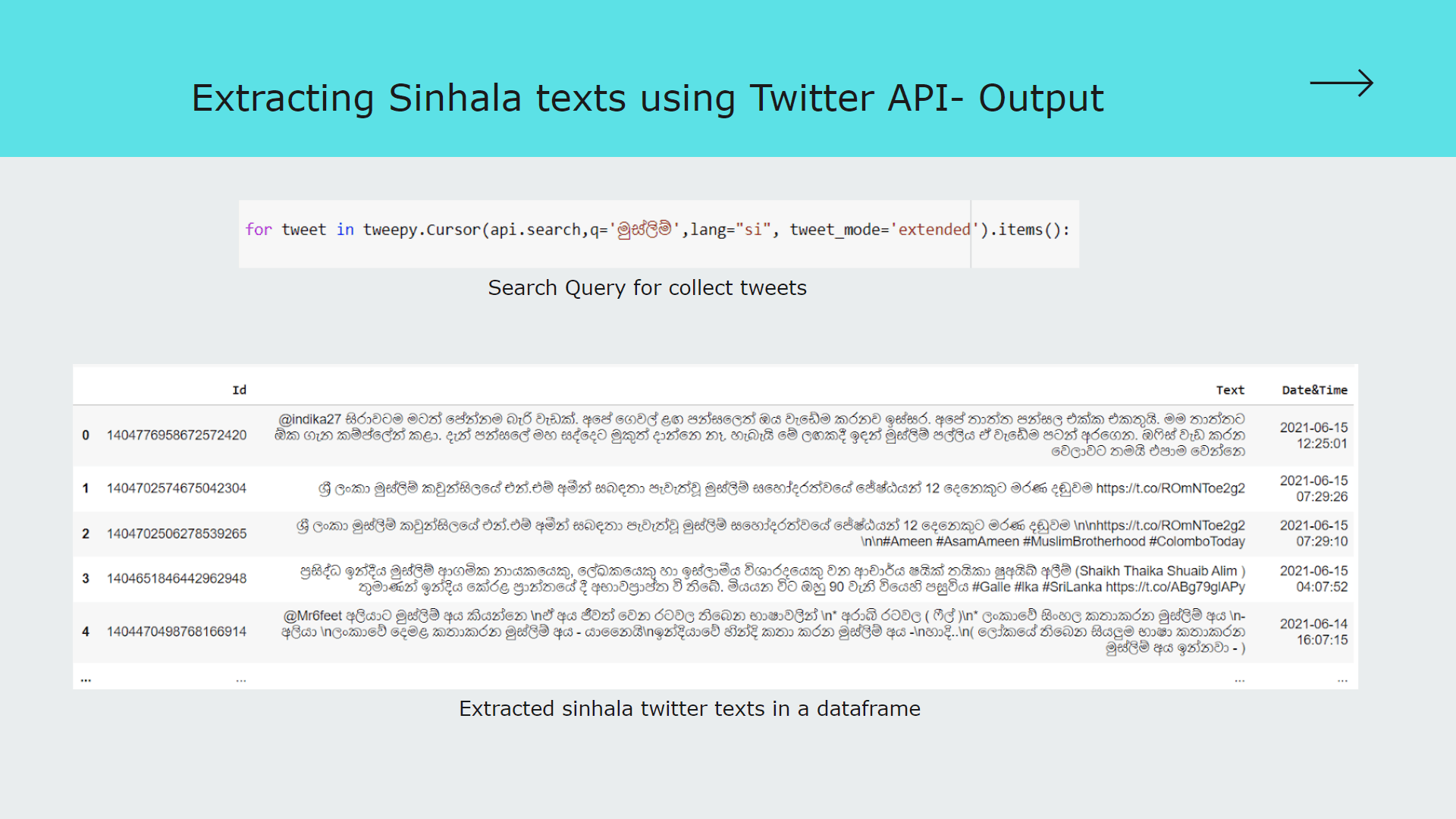
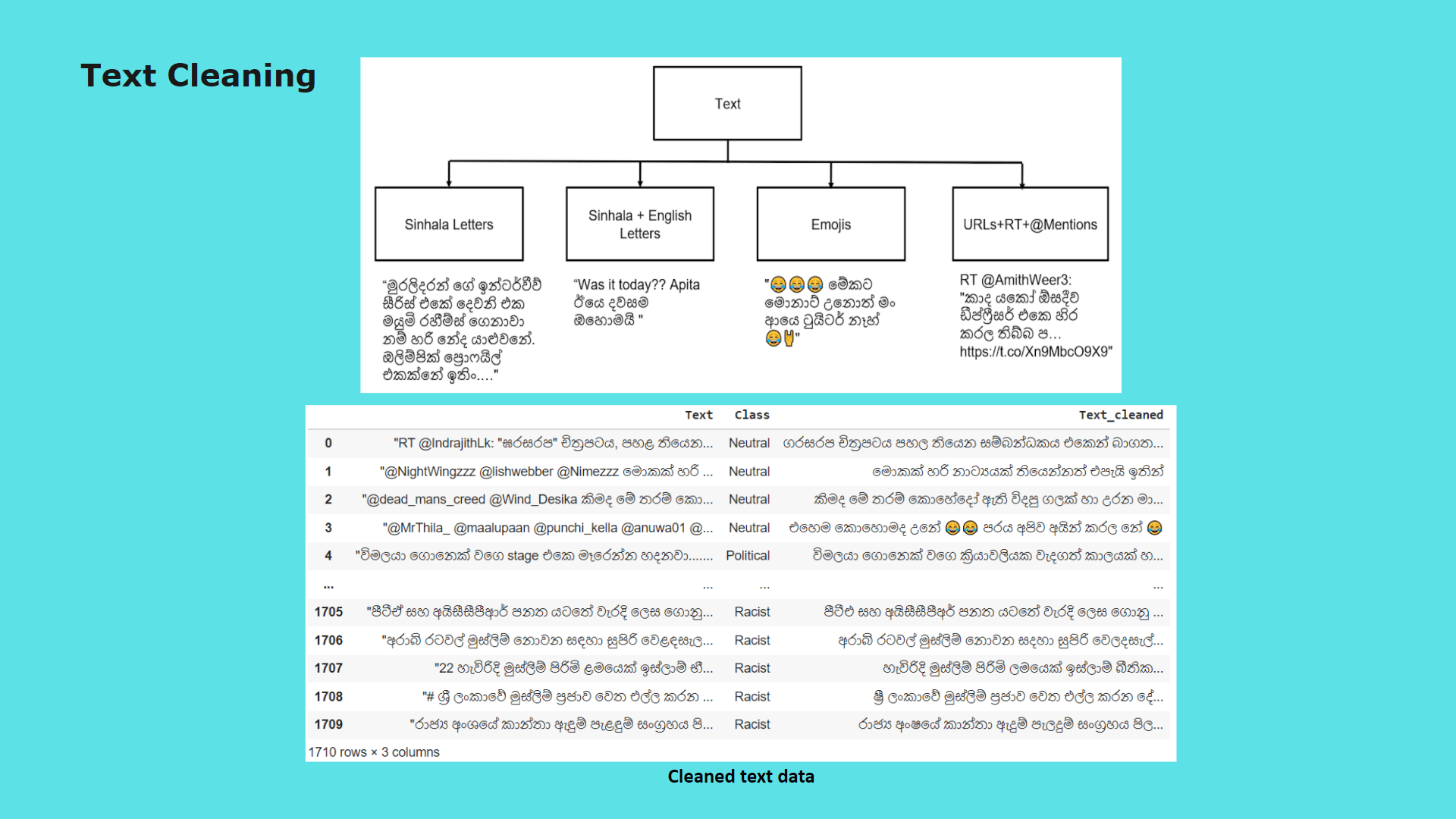
Module 2: Extract Sinhala twitter texts, Sinhala text preprocessing and Categorize tweet content considering Subject and Domain .
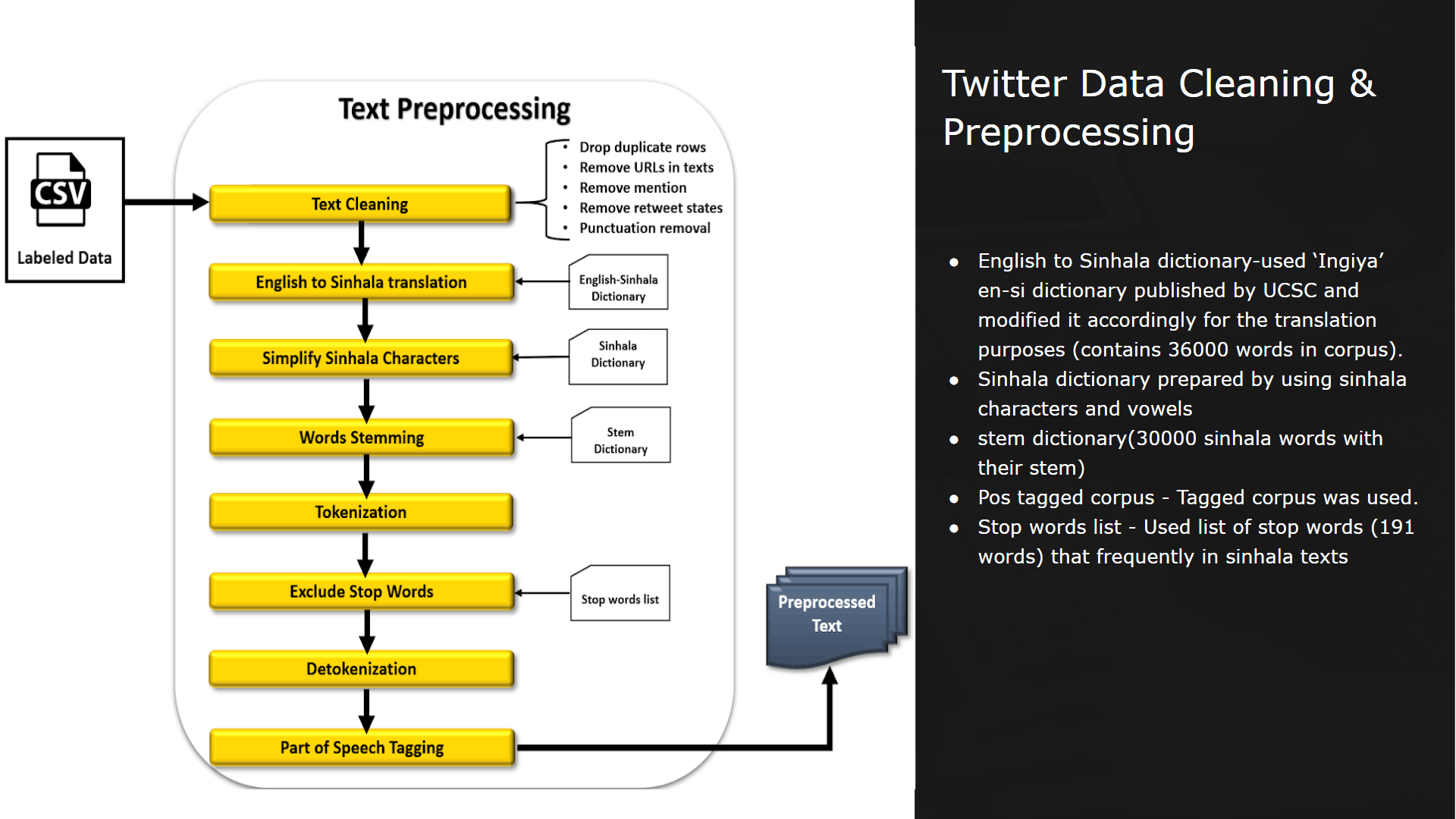
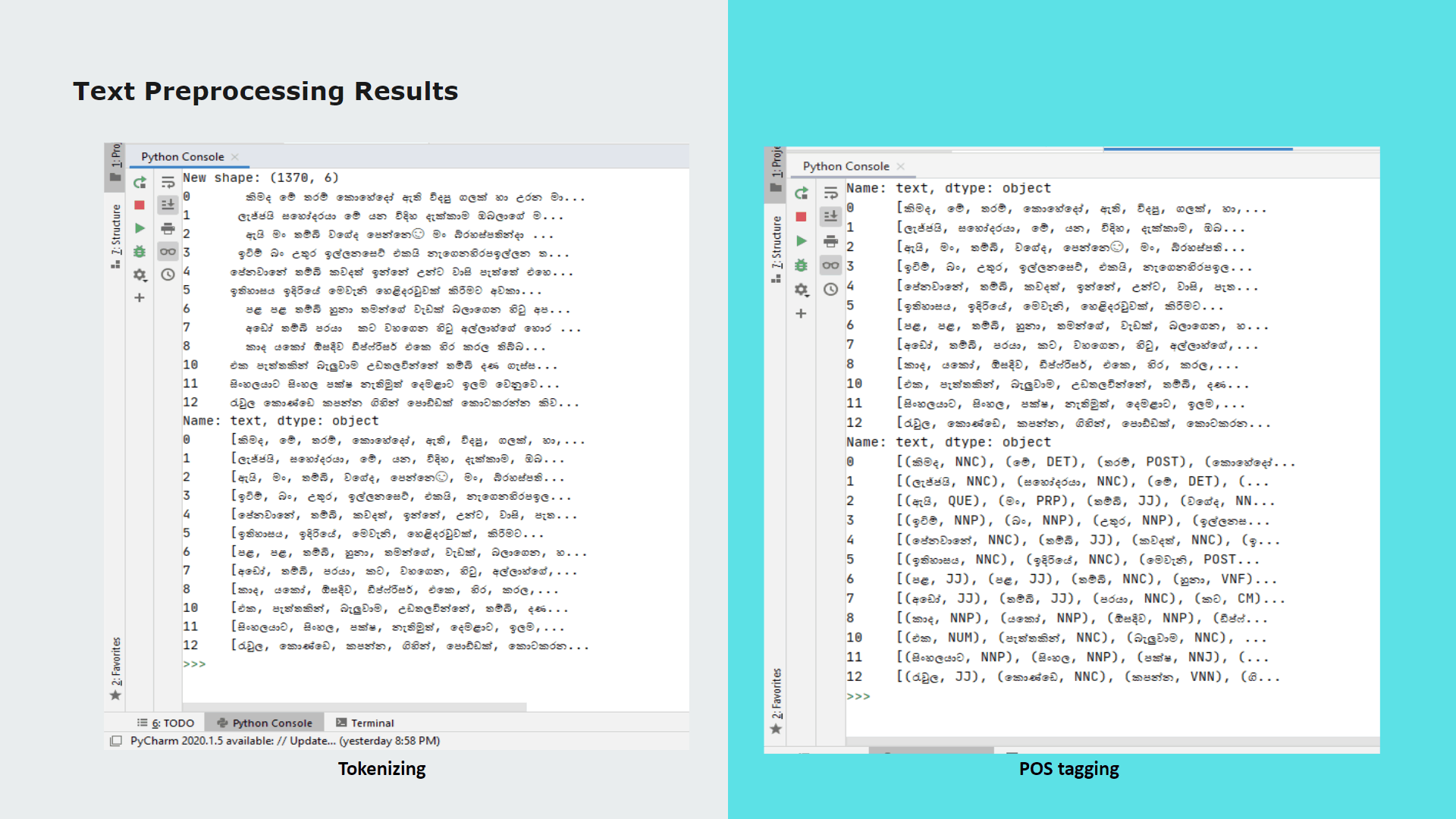
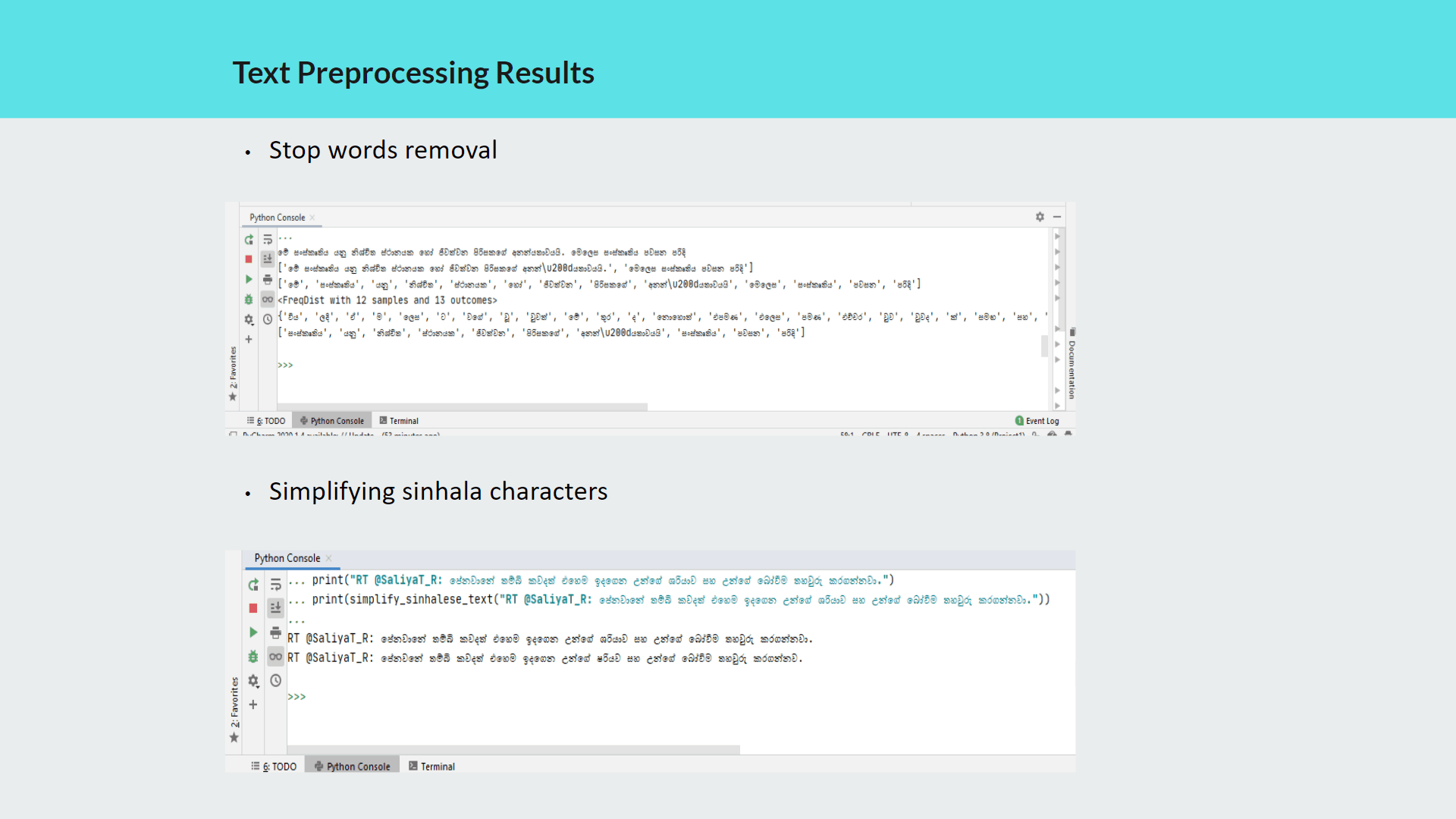
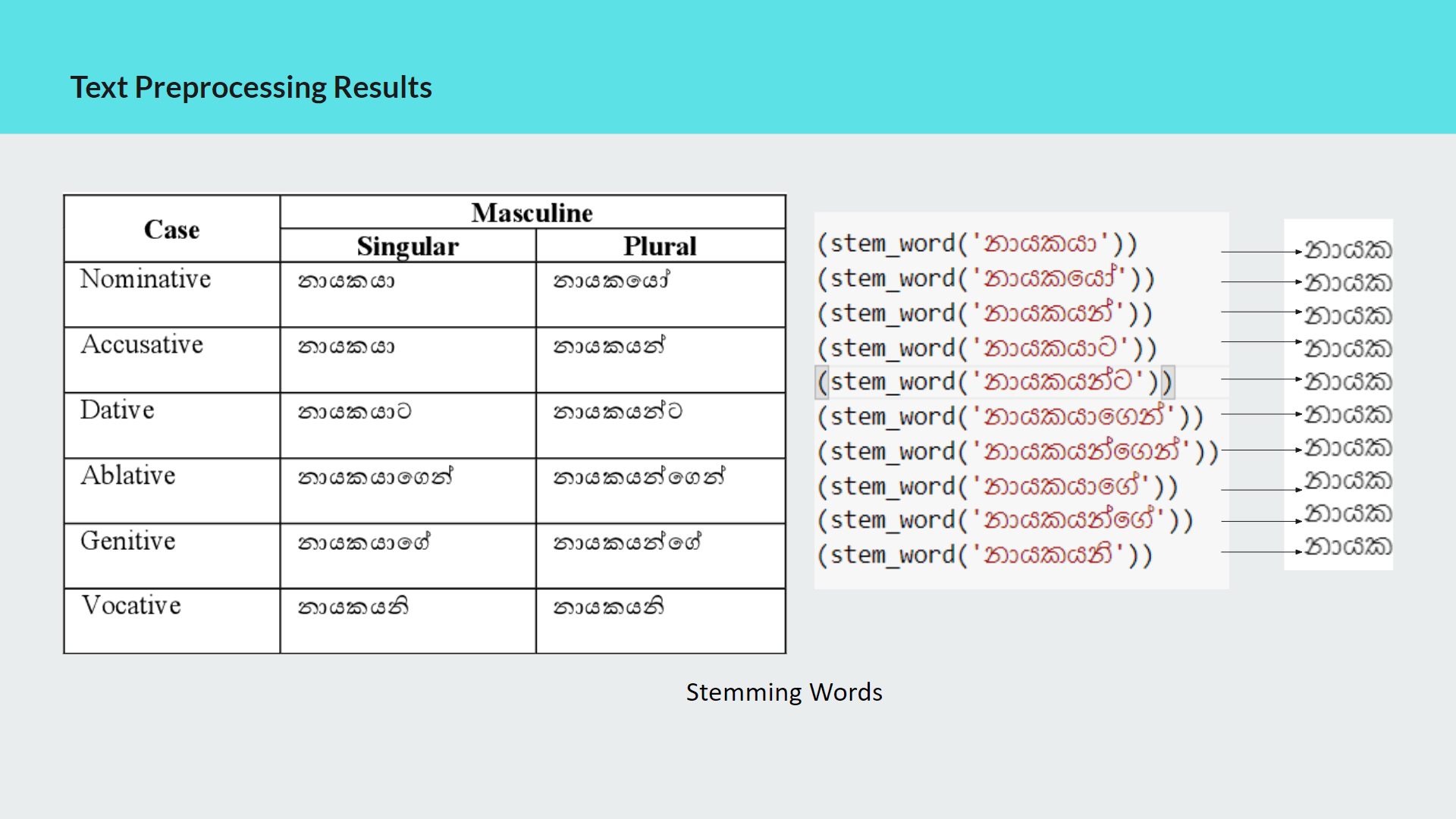
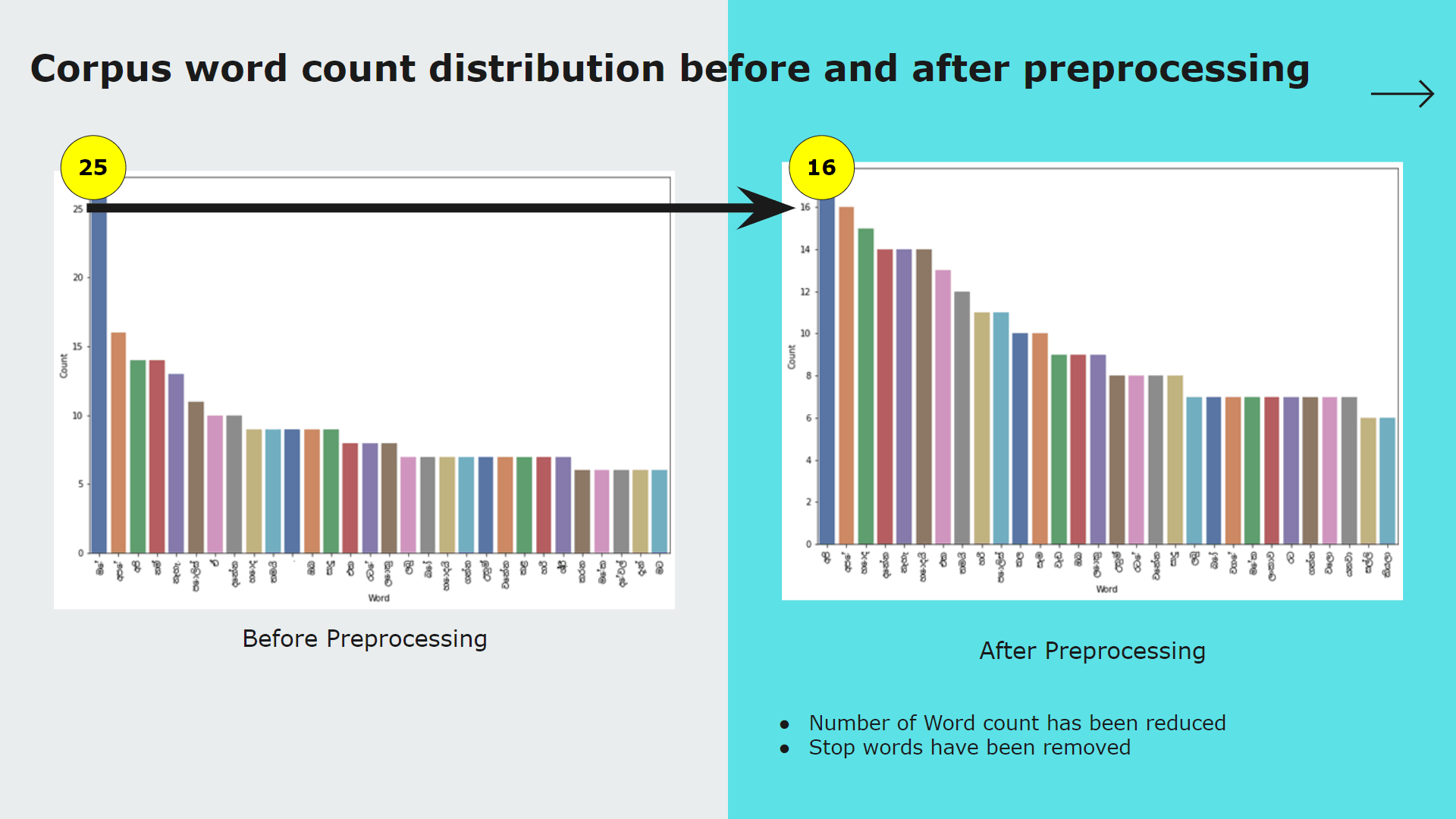
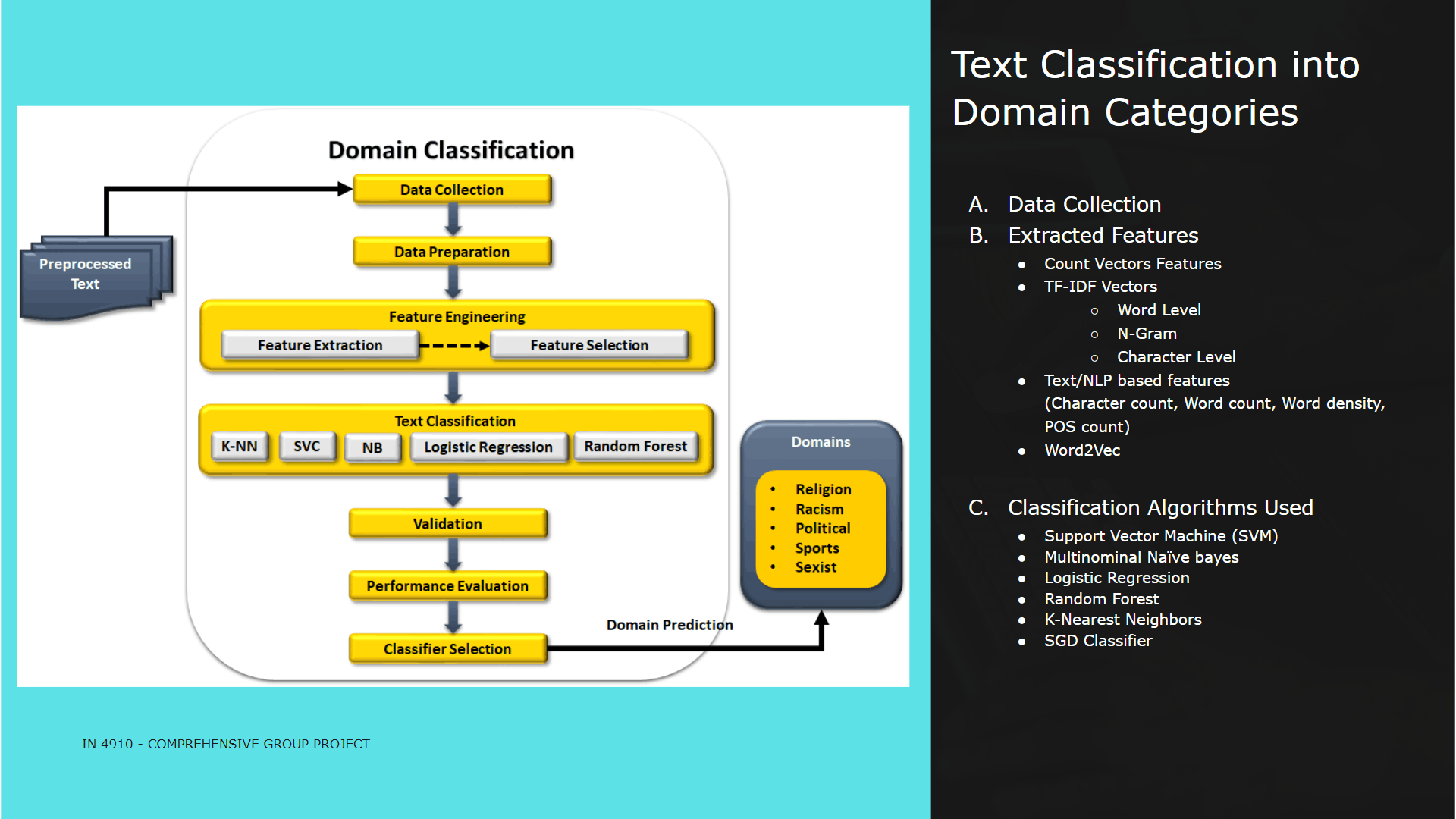
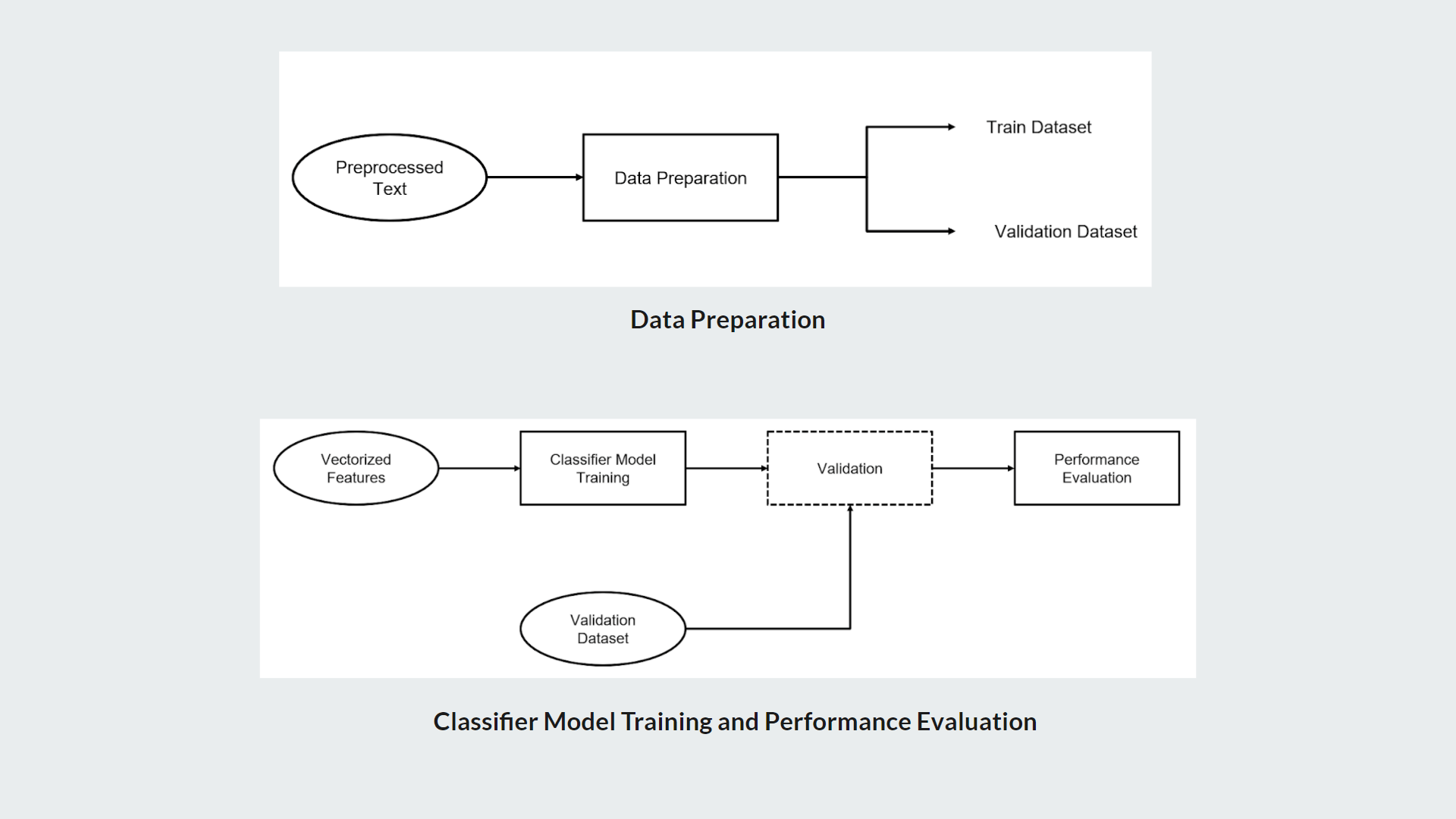
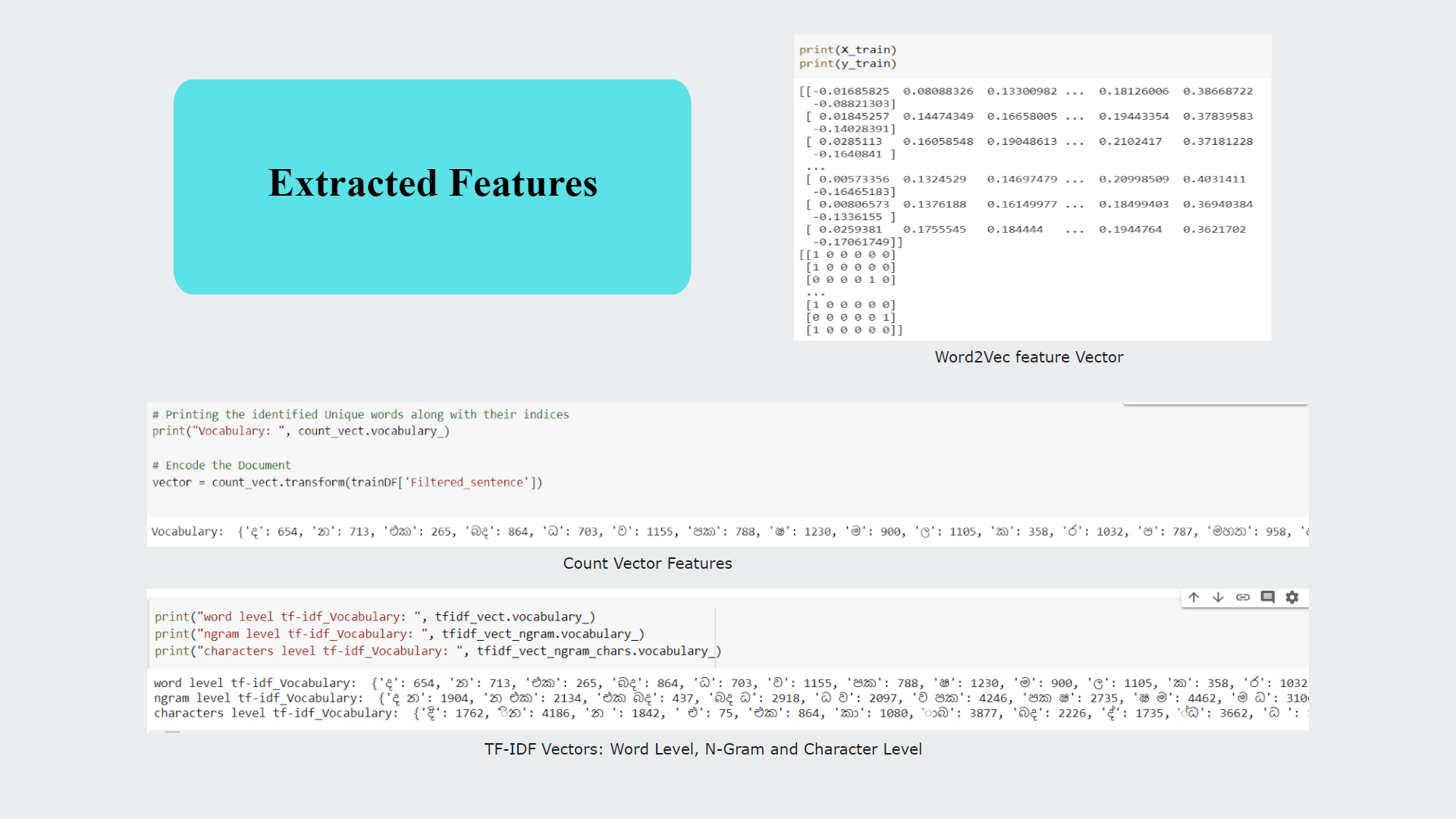
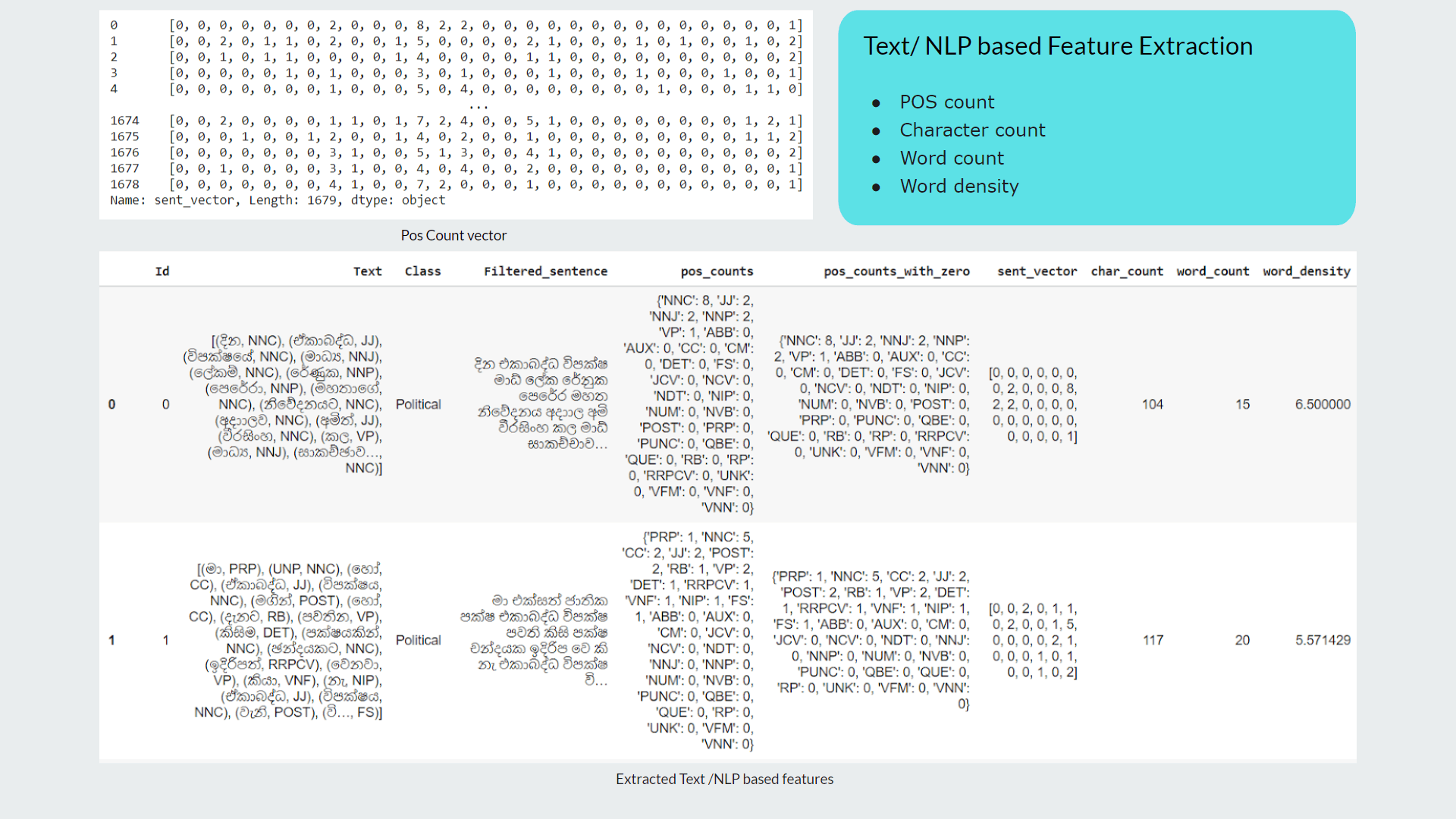
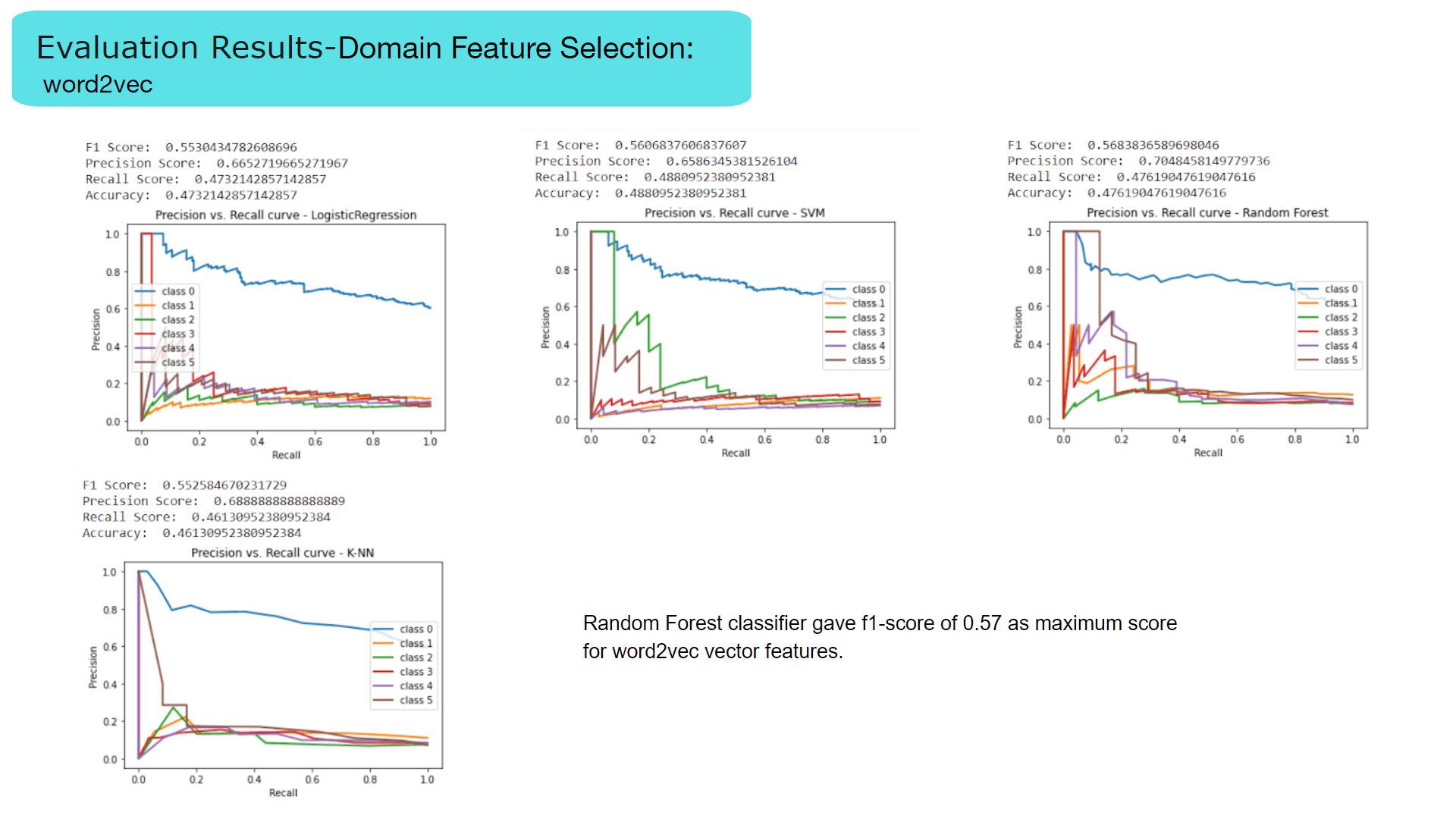
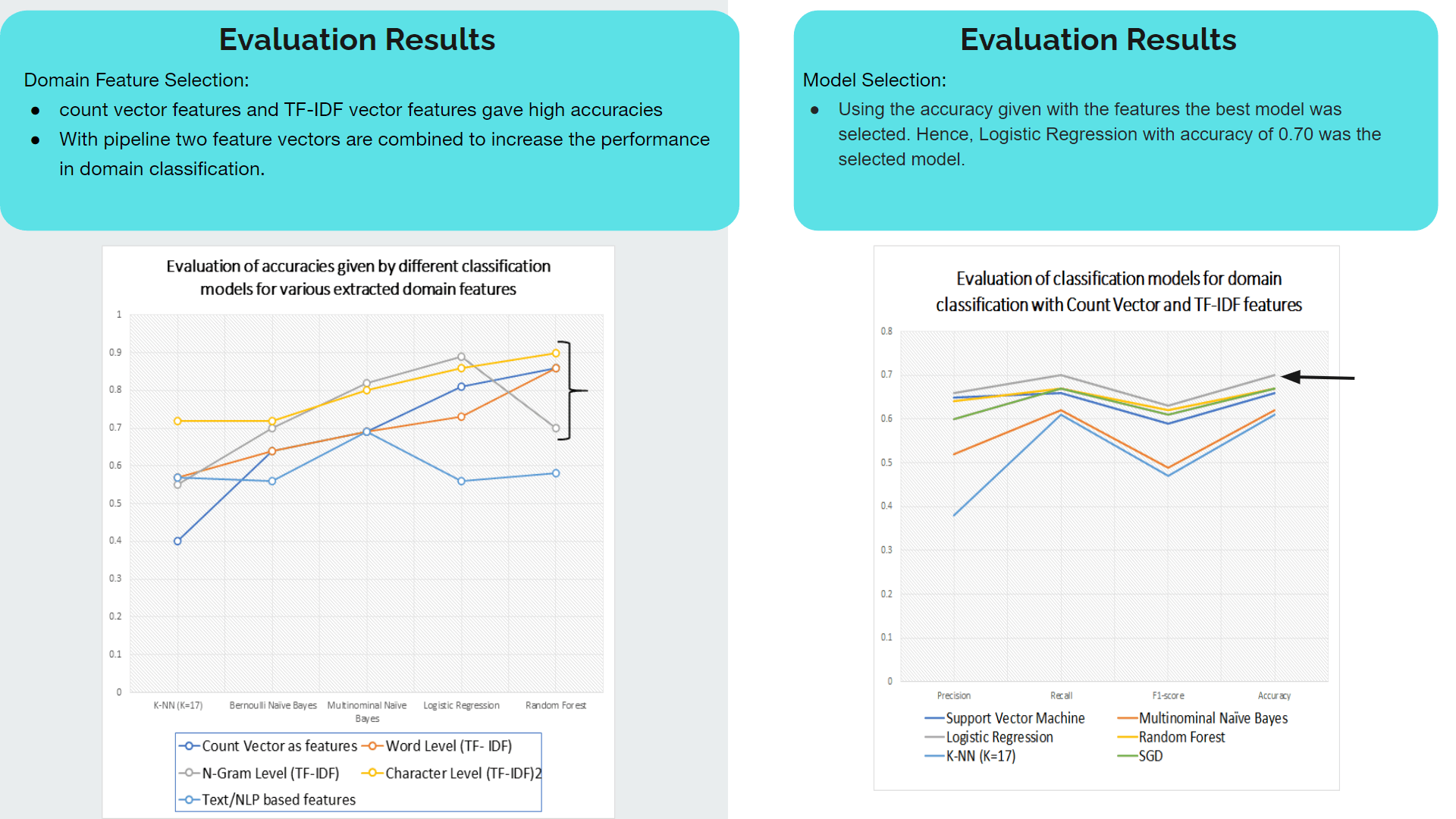
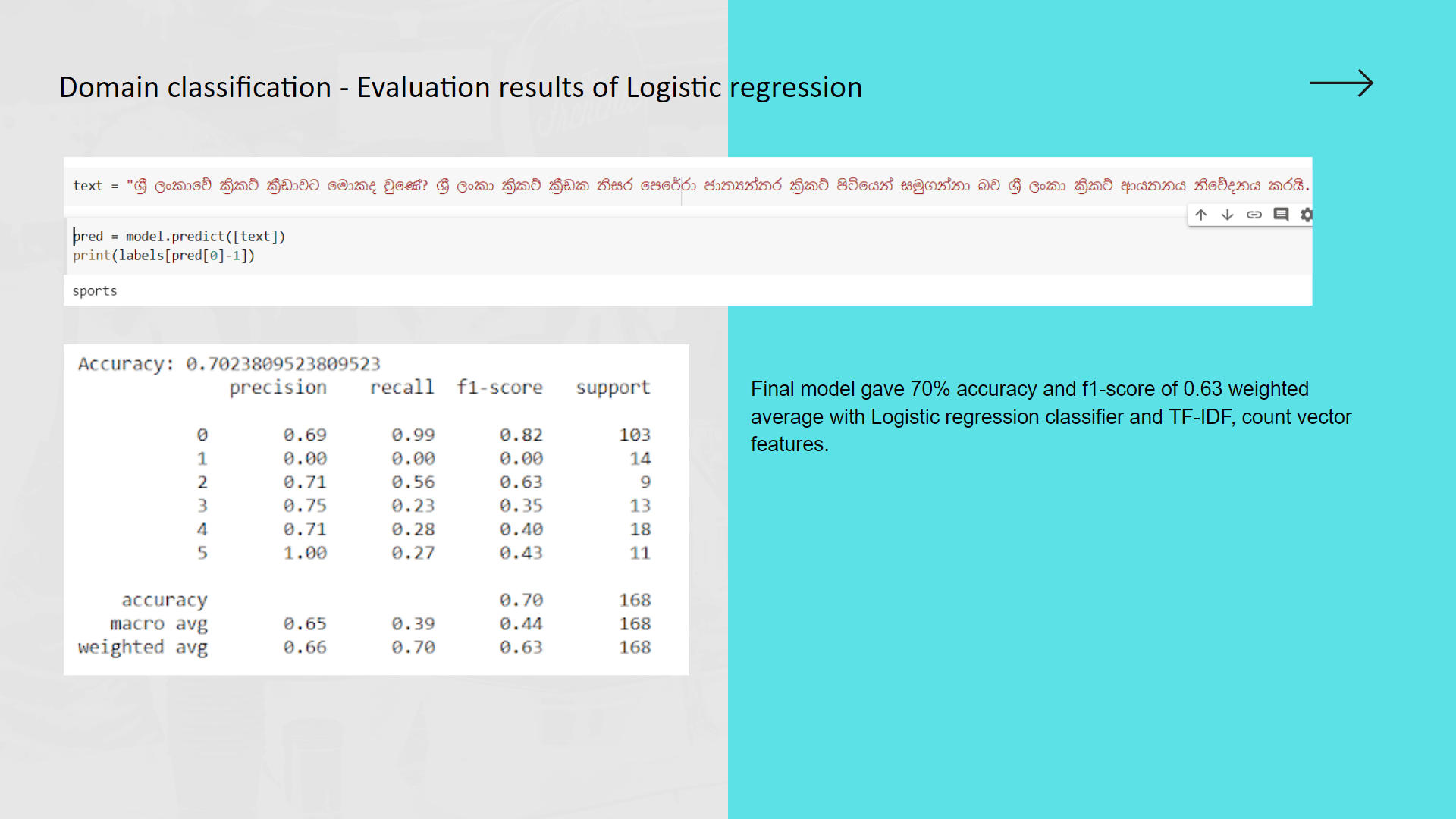
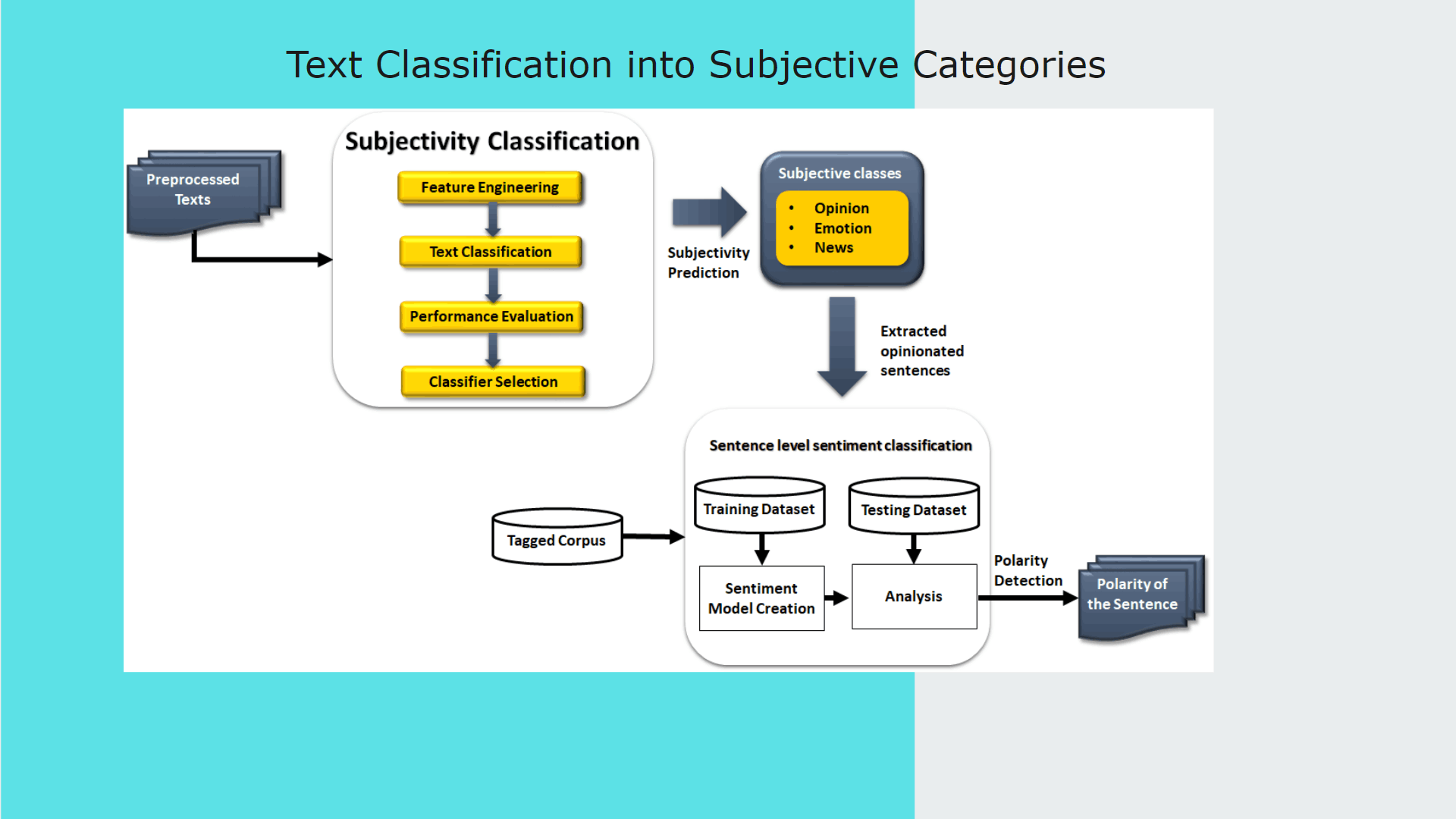
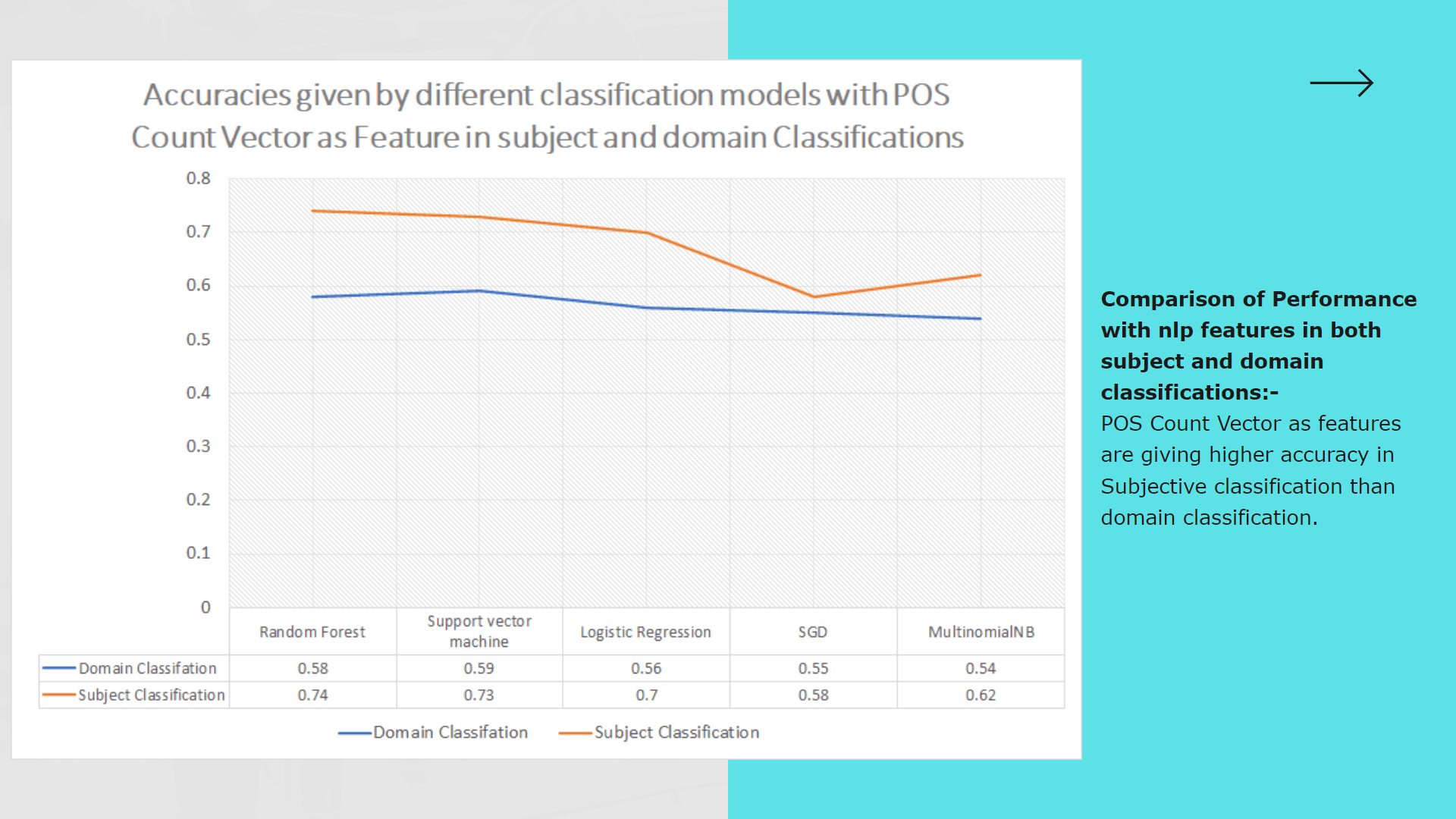
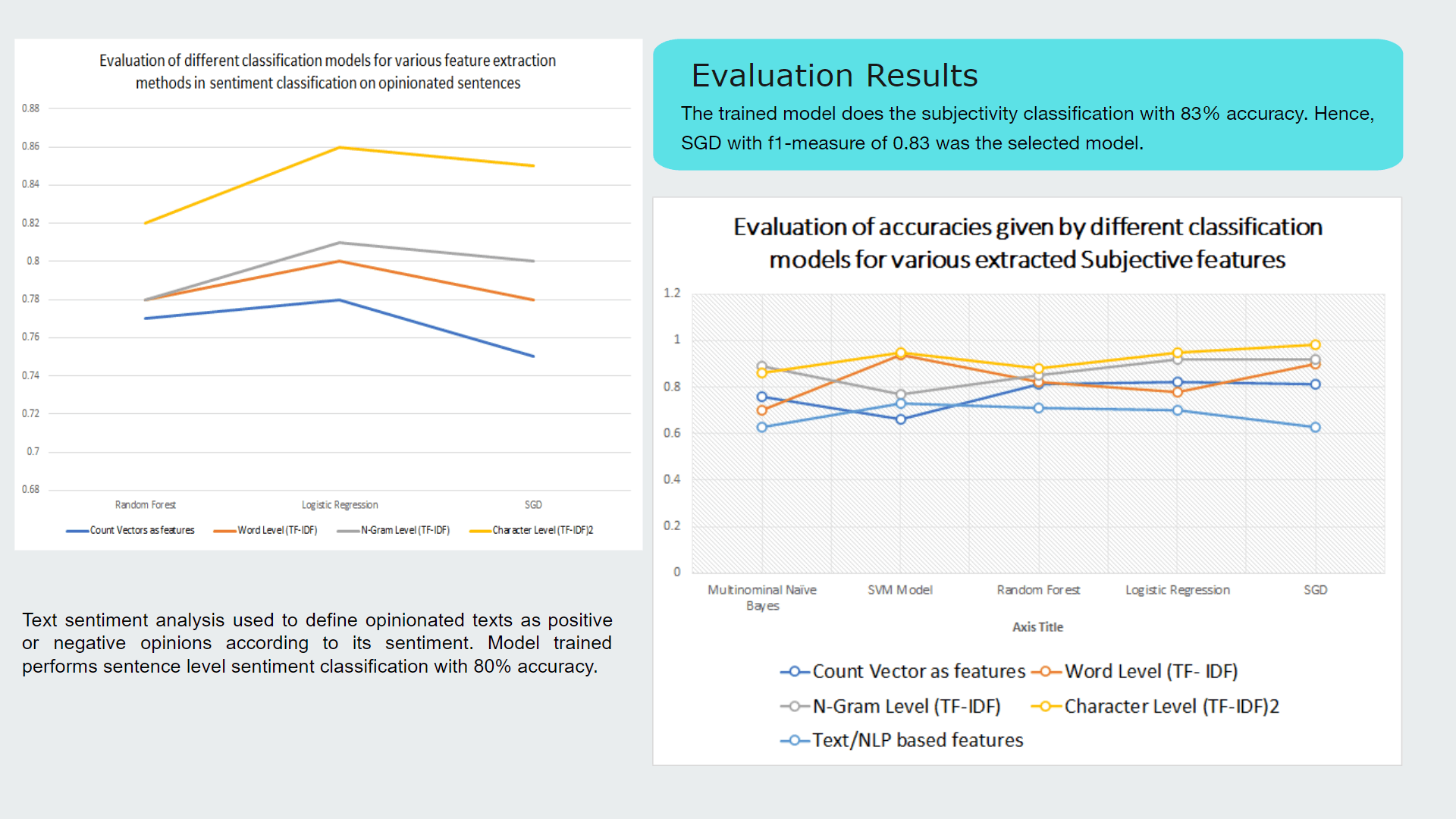
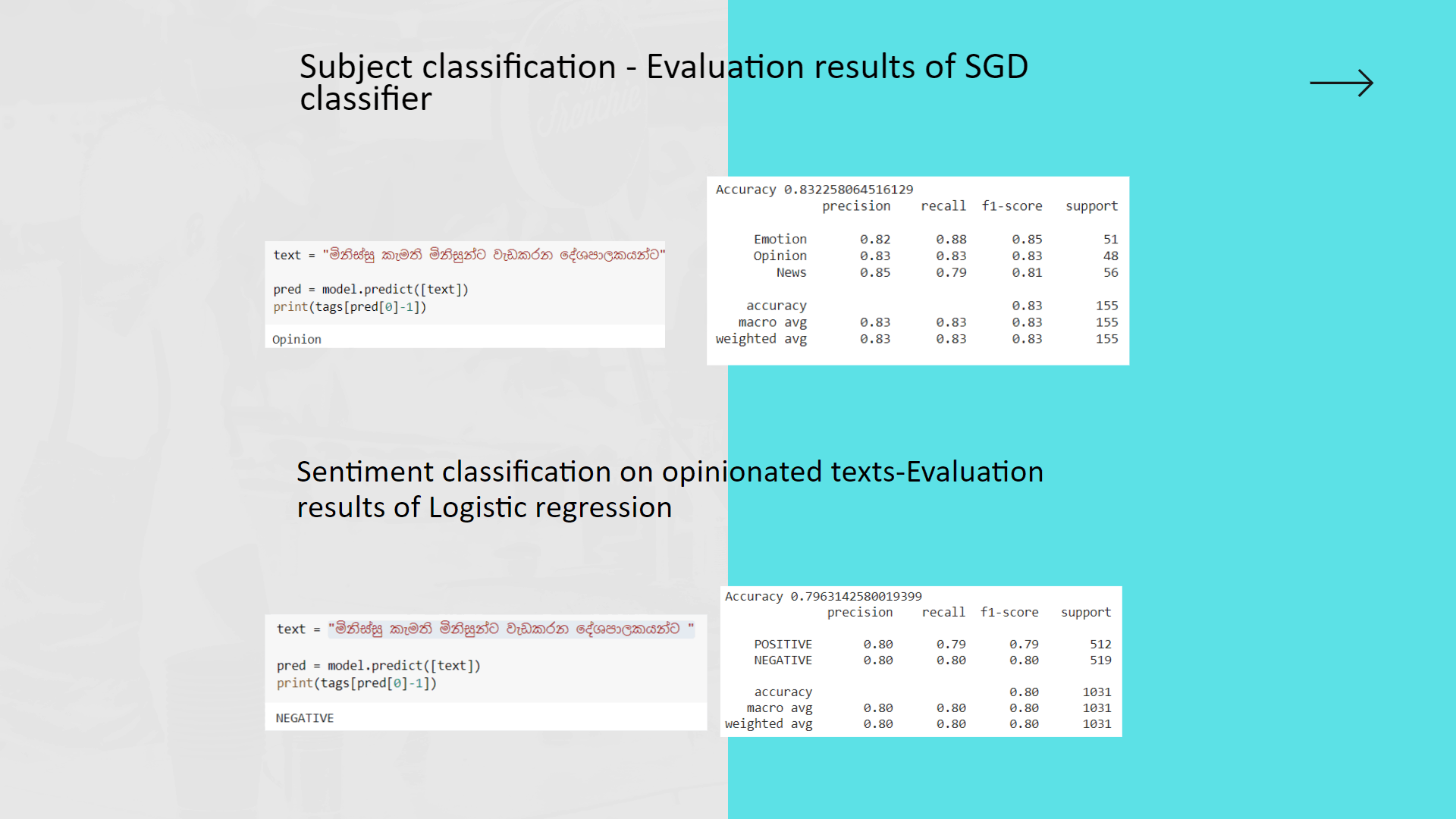
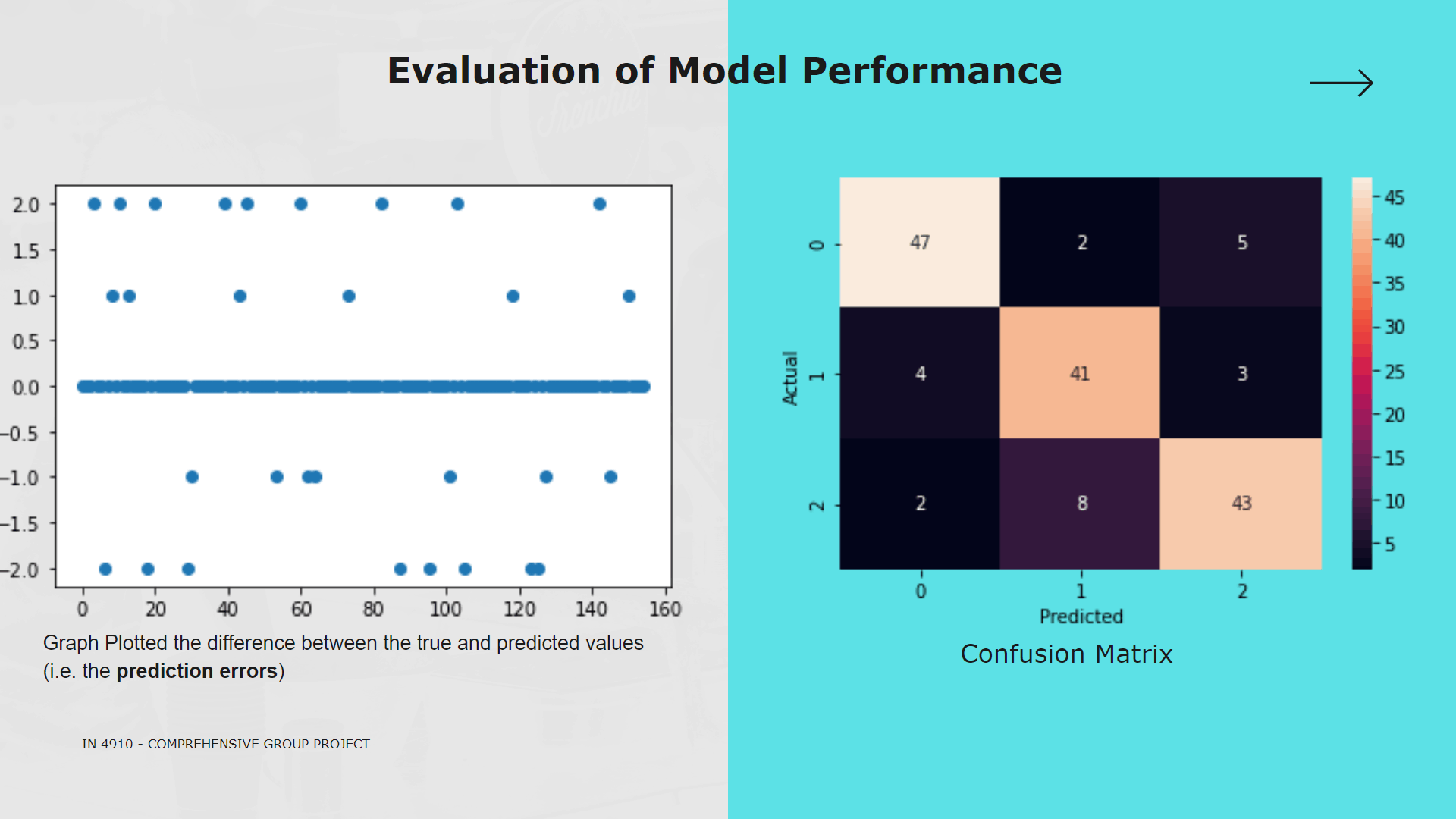
My contribution for the project was implementing the text preprocessing module of which outcomes are used as inputs for analysis, process of classifying sinhala texts found on Twitter into 5 primary domains(Religion, Racist, Political, Sports, Sexism and Others) and further classifying Sinhala texts into 3 subjective categories(Opinion, News, Emotion)
Purpose of implementing this module is to further analyze hate according to particular domain and subject classes to define severity level of the twitter text content.

Offline Website Maker